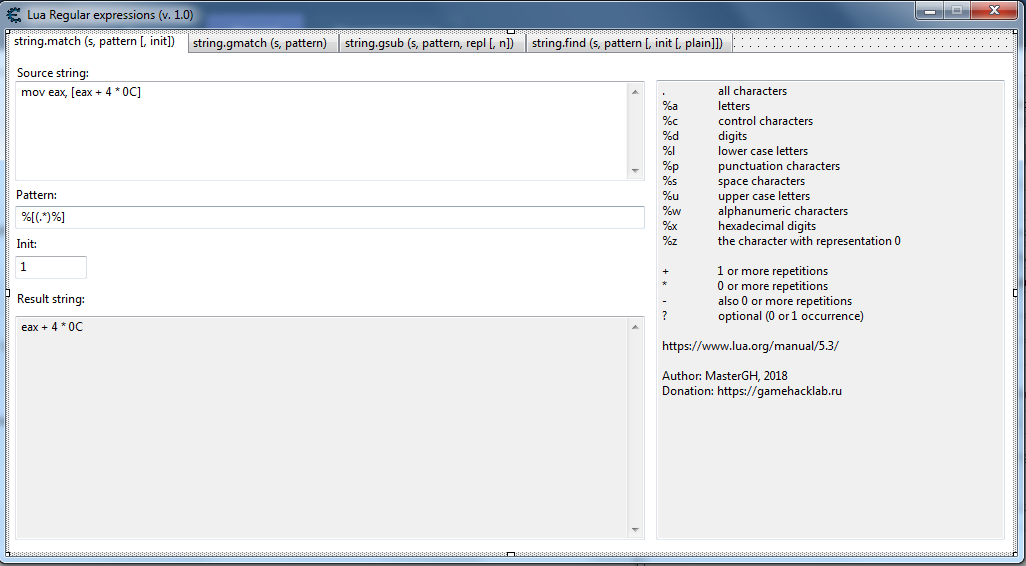
CE Tool Lua Regular expressions 2
-
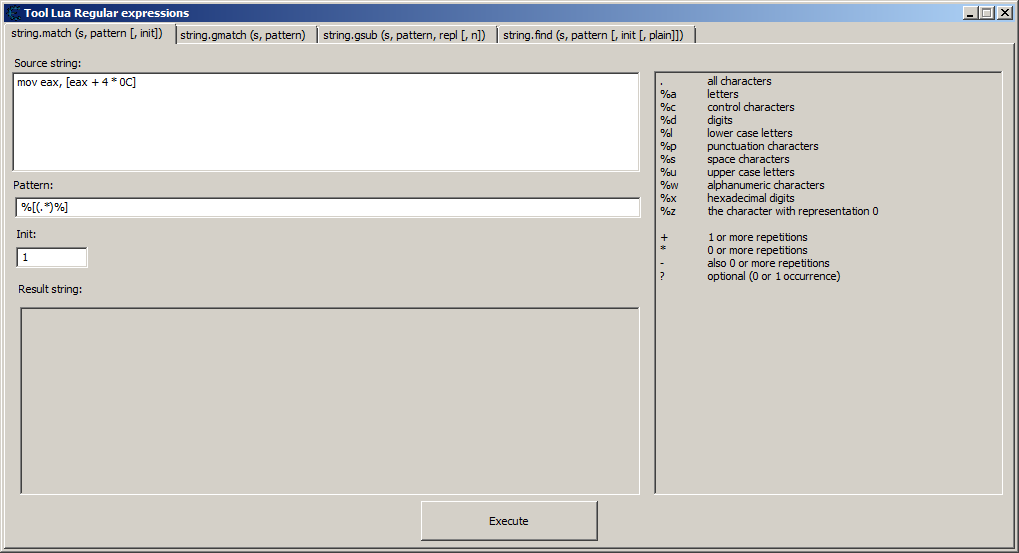
CT таблица для составления регулярных выражений 4-х функций
string.match (s, pattern [, init]) string.gmatch (s, pattern) string.gsub (s, pattern, repl [, n]) string.find (s, pattern [, init [, plain]])Функция string.gsub может принимать в аргумент функции "repl" таблицу (тогда будет замена по ключам значений из таблицы ) или в аргумент "repl" может попадать некоторая другая функция с аргументом найденного слова (тогда будет вызов этой другой функции при каждом захвате символа или слова). Более подробное в документации Lua 5.3
Еще несколько ссылок с практическим руководством
-
Lua поиск элемента до и после строки
Была задача получить два списка из документа, в котором было с пару десятков тысяч строк. На практике выяснилось, что искать текст после ключевого слова легче чем искать текст до ключевого слова. Об этом и будет дальше
В утилите "Lua Regular Expressions (v. 1.0)"
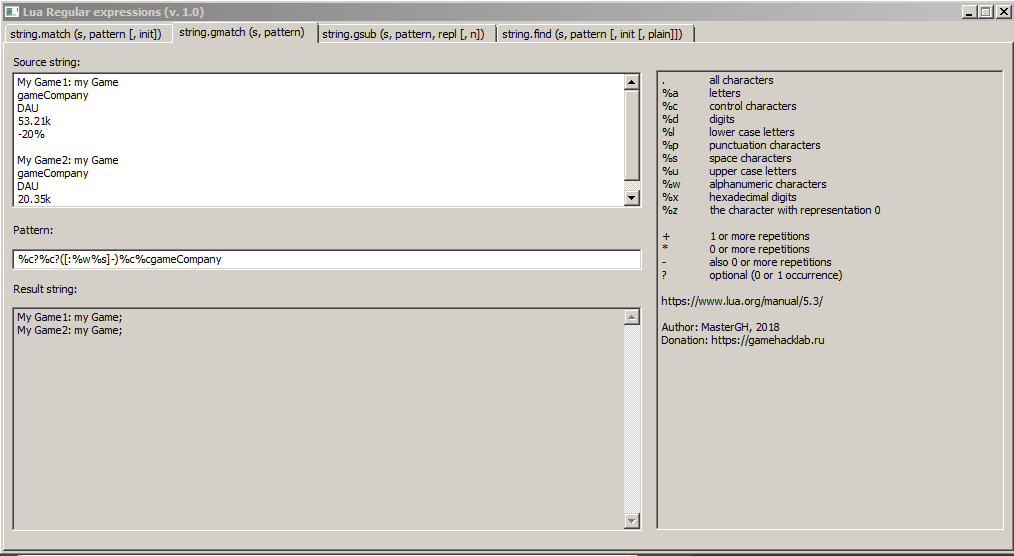
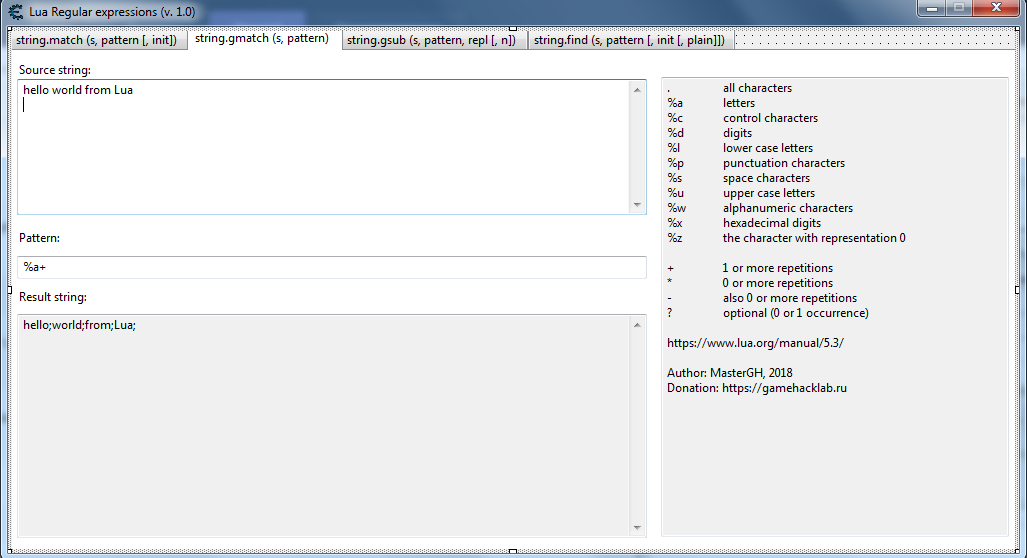
Текст во вкладке "gmatch"Game1
gameCompany
DAU
53.21k
-20%
Game2
gameCompany
DAU
20.35k
-20%Поиск элемента после строки:
"DAU "DAU%c%c(.-)%c%c"53.21k;20.35k;
Поиск элемента до строки:
"%c%c(.-)gameCompany%c%c"
(паттерн со двигом скобок для поиска предыдущей фразы)
не прокатит для вывода списка игр над фразой gameCompany;53.21k
-20%Game2
;Очевидно, можно сделать поиск по похожим фрагментам, которые идут последовательно сверху вниз.
Cначала добавим первую пустую строку и видим повторяющиеся фрагменты
"%c%cGame1%c%cgameCompany%c%c"пишем шаблон
".*%c%c(.-)%c%cgameCompany%c%c"и опять мимоGame1;53.21k
-20%Game2;
Потому что текст над Game2 пошел выше Game2. Тогда делаем захват, только первой фразы и дальше не идем
"%c%c(%w-)%c%cgameCompany%c%c"Game1;Game2;
И тогда все ок.Но это еще не все. Осталась первая пустая строка, которую добавили, если её удалить, тогда
"%c%c(%w-)%c%cgameCompany%c%c"Game2;
Не видит Game1.Значит мы можем убрать
%c%c,и будет"(%w-)%c%cgameCompany"Game1;Game2;
Дальше название игры может быть таким "My Game: my Game". Здесь и пробел и двоеточие. В таком случае текст уже будет
My Game1: my Game
gameCompany
DAU
53.21k
-20%
My Game2: my Game
gameCompany
DAU
20.35k
-20%
Пробуем
"(%w-)%c%cgameCompany"Game;Game;
Что не верно, т.к. захват одним(%w-)Мы должны в скобках развернуть фразу имени игры. В ней могут быть пробелы, числа, текст и двоеточие
'([%w%s]-)%c%cgameCompany'my Game; my Game;
Затем
([:%w%s]-)%c%cgameCompanyMy Game1: my Game;
My Game2: my Game;
Затем
%c?%c?([:%w%s]-)%c%cgameCompanyMy Game1: my Game;
My Game2: my Game;Вот и все. Если попариться один раз, то тексты уже парсить будет гораздо быстрее.
Так я вывел столбы DAU и названий игр в таблицу, что было в районе 500 строк из пару десятков тысяч строк
p.s. Текст в консоли Lua отличается %c%c, а %с
p.s.p.s. Можно раcсплитить текст по
"/n/r"или"/n"в таблицу строк и по индексам данных находить предыдущую или последующую фразу. Но мне проще две строки ввести"%c?%c?([:%w%s]-)%c%cgameCompany"и"DAU%c%c(.-)%c%c"